Как сделать русскую озвучку иностранного фильма.
Часть 1
Честно говоря, достали уже изготовители DVD продукции. То ли непроходимым ламеризмом, то ли полнейшим пофигизмом, помноженным на глубочайшее неуважение потребителя. Как вам нравится факт размещения неотключаемых рекламных роликов перед фильмом! А кривое (например, корейский фильм "Musa") транскодирование NTSC->PAL и дикий авторинг? Это то, что касается так называемых "лицензионных" PAL версий для богатых. В народных дисках кривость авторинга тоже наблюдается, но они, по крайней мере, содержат родную версию изображения и звука. Мне же хочется заострить внимание на главной проблеме, присущей как дорогим, так и народным версиям, поскольку источник её кроется в единой, имхо, материально-технической базе. Это озвучка. Да! Задолбали! Какой придурок подбирал эти голоса, годные только на то, чтобы озвучивать рекламу на сельских студиях кабельного ТВ? Кому пришло в голову, что это может быть лучше оригинального голоса актёра? Секрет правильного дубляжа утерян (вспомните любой из фильмов с де Фюнесом или Бельмондо, озвученный в 70-х годах), похоже, навсегда. Одна и та же команда с одними и теми же голосами одними и теми же интонациями производит стереотипную серенькую продукцию. При этом оригинальное звучание саундтрека убивается напрочь, поскольку записывают они себя на 6-8 децибел громче необходимого уровня. Окончательно меня добил DVD "Леон", в котором русская версия мало того, что просто стереофоническая, так ещё и наложена на французский дубляж! Короче, весь кайф многоканального звука безвозвратно обломан. Лично меня устраивает только одноголосая дикторская озвучка с более менее нейтральными интонациями. Её прелесть заключается в том, что, при правильно подобранном балансе громкости оригинальных диалогов с голосом диктора, через некоторое время начинаешь слышать только родные голоса актёров, улавливая каждую интонацию, в то же время понимая всю суть.
Метод, который я хочу здесь описать, не претендует ни на полноту, ни на оригинальность и наверняка известен людям, профессионально занимающимся озвучанием, и уже был частично описан в сети, правда, с использованием других инструментов, избытком технических деталей и страшными сомнениями, что вообще кто-то сможет повторить эту ужасающе трудоёмкую процедуру :). На самом деле, это очень просто. Профессионалов просьба не беспокоить себя дальнейшим чтением. Нового ничего не будет. Статья подразумевает элементарные знания в области компьютерных технологий обработки аудио и видео и отражает лично моё вИдение озвучки материала.
Итак, что мы имеем? DVD с оригинальным AC3 звуком и файл перевода. Не знаю, где вы возьмёте перевод. Можно из сети скачать, можно диктора пригласить, можно самому наговорить. Главное, что он есть. И приличного качества. Способы очищения и реставрации плохо записанных переводов я здесь рассматривать не буду, это тема отдельного разговора.
В качестве инструмента я буду использовать Vegas Video. Почему не Nuendo? Потому, что мне так удобнее :) И ещё потому, что я не музыкант. Я не умею и не хочу работать в Nuendo, если есть программа, которая мне понятна без изучения справочной системы. А возможности Вегаса по озвучке легко перекрывают все потребности post-production радио и телевещания, а тем более любительские. Голос из зала: "А вы знаете, уважаемый докладчик, что алгоритм микширования звука в Vegas менее совершенен, нежели аналогичный в Nuendo, что приводит к лёгкому замутнению верхней вуали нижней середины басов и потере прозрачности послезвучия кастаньетов в пьесе Артурио Кевадэса "Обломинго" на двадцатой секунде воспроизведения, а также
некотоpую холодность и отстpанённость подачи музыки и постоянно пpисутствующую, хотя и малозаметную "металлическую" окpаску в веpхней части сpеднечастотного диапазона и в области более высоких частот музыкального сигнала!" - В сад! Мы вообще собираемся делать недопустимые вещи: конвертировать сигнал из формата сжатия с потерями информации в в него самого.
Традиционно любые tutorial по DVD re-autoring проводятся на примере DVD "The Matrix" американского производства. Не будем нарушать традиций :) Лично у меня его нет, и реально скриншоты будут с дорожками от "Professional", но я прикинусь, будто это от "Матрицы" :)
Потрошение DVD диска выходит за рамки этой статьи, по крайней мере, пока. Сделайте это любым удобным для вас способом и распакуйте AC3 файл в отдельную диру. Места понадобится много, гигабайт 5-6 на проект. Когда я говорю "распакуйте AC3 файл", я имею ввиду шесть независимых моно WAV файлов. Пример виден на скриншоте сверху. Положите туда же файл перевода. Он может быть практически в любом формате: WAV, MP3, OGG... Всё, фантазия закончилась :) Нужно учесть, что Вегас не умеет самостоятельно распаковывать AC3, хотя с кодированием справляется прекрасно. Кстати, если на DVD есть дорожка DTS, то лучше распаковать именно её, поскольку качество звука в DTS, как правило, выше AC3, так как используется более высокий bitrate. Кодировать всё равно будем в AC3 :) В качестве подготовительных действий ещё можно закодировать изображение в DivX для контроля синхронизации звука и видео. Главное здесь fps, поэтому можно использовать минимальное разрешение и самое фиговое качество кодирования. Процесс займёт где-то полчаса. AC3 распаковывается дольше :) Чем пользуюсь я? Диски я потрошу DVDDecrypterом в режиме Stream Processing, а AC3 и DTS распаковываю BeSweet.exe и azidts.exe соответственно.
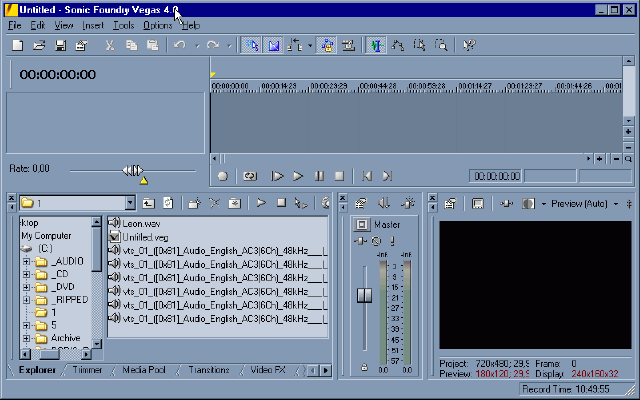
Теперь о настройках Вегаса. Жмём Alt+Enter, чтобы открыть окно Project Properties.
Закладка Video.
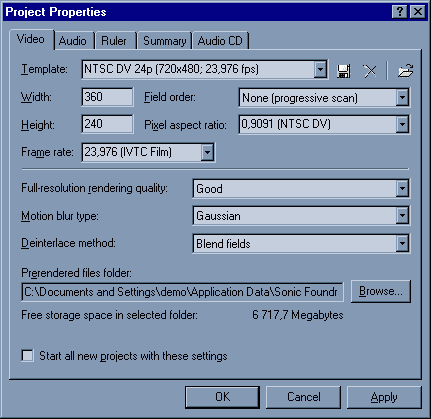
Поскольку оригинал моего фильма NTSC c 29,976 fps, но кодировал я его напрямую из DVD2AVI c включённым Forced FILM и половинным разрешением, я выбираю соответствующий Template и корректирую Width и Height. Домашнее задание: догадайтесь, что нужно сделать, если исходник PAL.
Закладка Audio.
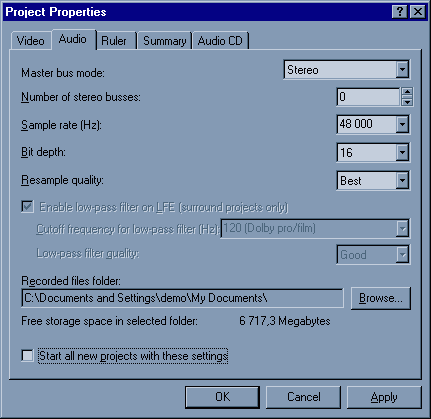
Вот и ягодки начались. Это самая главная для нас закладка. Здесь нужно выставить Master bus на Stereo, Sample rate на 48 кГц и Resample quality на Best. Stereo - вообще-то и моно бы хватило, нам нужно просто смикшировать центральный канал с переводом, Sample rate и так понятно, а вот Resample quality надо пояснить. Неважно, какого качества файл перевода мы подсунем Вегасу, во время микширования он преобразует его к указанной частоте дискретизации максимально качественно.
Закладка Ruler.
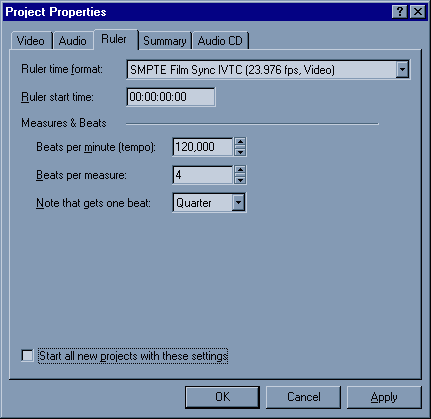
Здесь просто надо выставить правильный формат отображения времени на таймлайне.
Нажимаем OK и приступаем к работе.
Первым делом нужно положить на таймлайн дорожки центрального канала и перевода. (А также ваш DivX, если вы его делали. Я не делал, поэтому его и не видно на скриншотах.) Это делается через Ctrl+O или простым перетаскиванием файлов из окна Explorer Вегаса. При перетаскивании нужно подогнать файл в начало таймлайна. Подождём пару минут, пока Вегас проанализирует файлы и прорисует все дорожки. Чем меньше размер файла, тем быстрее процесс. Это значит, что, например, MP3 файл, аналогичный по времени звучания, прорисуется в несколько раз быстрее. Кстати, Vegas, в отличие от того же Nuendo, не будет создавать proxy-файл, а будет работать с MP3 напрямую. Но это не означает, что распаковка не производится вообще :)
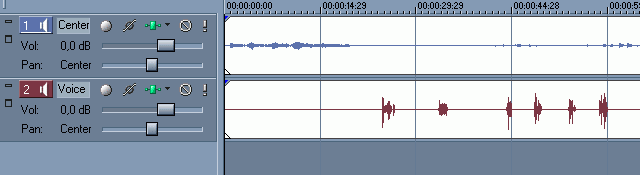
Итак, что мы видим? Вегас самостоятельно создал аудиотреки и положил на них файлы. Как видно из скриншота, я сразу же вбил названия треков. Сделано это специально для вас, поскольку в реальном проекте я никогда этого не делаю, поскольку и так знаю, где у меня что лежит :) Первым делом убьём всю аудиообработку, которая автоматом установилась. Правой кнопкой мышки (далее ПК - правый клик) щёлкнем на  и выберем в меню Delete All. Это не значит, что мы вообще отказываемся от обработки, нет. Диктора мы ещё как будем обрабатывать, а вот центральный канал нам нужно сохранить в максимальной неприкосновенности. Нажмём Ctrl+S и сохраним наш проект. Я человек ленивый, поэтому почти всегда сохраняю проекты под именами, предложенными программой :) Мне представляется полезным нажимать Ctrl+S каждый раз, когда я ухожу покурить или за очередной чашкой кофе. Бывает, задумаешься над очередным проектом, в голове пустота, а левая рука на автомате - Ctrl+S, Ctrl+S, Ctrl+S... Н-да... Надо бы к доктору наведаться... Но я отвлёкся, вернёмся к нашим баранам. Во время подгонки голоса переводчика нам понадобится растягивать и сжимать таймлайн. Разберитесь с этим сами. Маленькая подсказка: попробуйте потаскать влево-вправо полосу прокрутки таймлайна за её край
и выберем в меню Delete All. Это не значит, что мы вообще отказываемся от обработки, нет. Диктора мы ещё как будем обрабатывать, а вот центральный канал нам нужно сохранить в максимальной неприкосновенности. Нажмём Ctrl+S и сохраним наш проект. Я человек ленивый, поэтому почти всегда сохраняю проекты под именами, предложенными программой :) Мне представляется полезным нажимать Ctrl+S каждый раз, когда я ухожу покурить или за очередной чашкой кофе. Бывает, задумаешься над очередным проектом, в голове пустота, а левая рука на автомате - Ctrl+S, Ctrl+S, Ctrl+S... Н-да... Надо бы к доктору наведаться... Но я отвлёкся, вернёмся к нашим баранам. Во время подгонки голоса переводчика нам понадобится растягивать и сжимать таймлайн. Разберитесь с этим сами. Маленькая подсказка: попробуйте потаскать влево-вправо полосу прокрутки таймлайна за её край  или покрутить колёсико мышки над таймлайном. Ширина (она же высота :) регулируется тасканием вверх-вниз нижнего края дорожки в области регулировок, например, под словом Pan:.
или покрутить колёсико мышки над таймлайном. Ширина (она же высота :) регулируется тасканием вверх-вниз нижнего края дорожки в области регулировок, например, под словом Pan:.
Жмём Anykey (далее - пробел :) и слушаем, что у нас получилось. Пробел работает интуитивно понятно: нажал - воспроизведение, нажал второй раз - стоп. Если во время воспроизведения щёлкнуть левой кнопкой мышки (далее ЛК - левый клик) в пустой области под треками, воспроизведение продолжится с места клика, если на дорожке, то в это место просто установится курсор, а дорожка станет доступной для редактирования. Например, хотели мы нажать Ctrl+S, но промахнулись и нажали просто S. Мамочка рОдная! А дорожка-то разрезана! :)))) Запомнили? Кнопка S разрезает выбранную дорожку в позиции курсора. Резать нам придётся много. Однако, при прослушивании мы столкнулись с тем, что диктор читает текст чуть раньше или чуть позже. Проблема устраняется простым тасканием дорожки влево-вправо. Таскать можно даже во время воспроизведения. Чтобы нам вольготно было это делать, удалим тишину в начале дикторского трека.
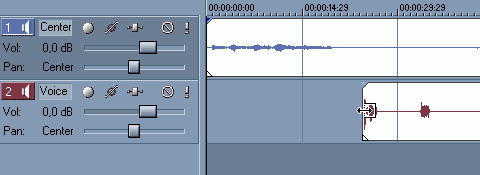
Делается это так: подведите курсор мышки в самое начало трека в его середине, пока он не примет форму, как на скриншоте, ЛК и тащим мышкой до первого слова. Voi la. Теперь трек можно таскать и влево и вправо. Домашнее задание: разрежьте трек между словами и удалите тишину. Теперь можно позиционировать не только трек, но и каждое слово в отдельности, подрезАть лишние паузы и оговорки.
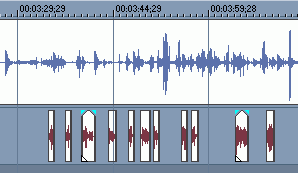
Теперь несколько советов по аппликации.
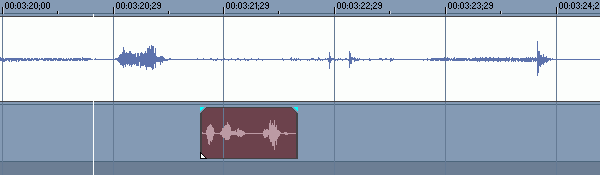
Сначала всегда нужно дать слово актёру, чтобы мы прочувствовали его голос от и до, и только потом давать перевод. В случае с короткими фразами это сделать просто, немного сложнее в диалогах.
Рассмотрим случай спокойного диалога.
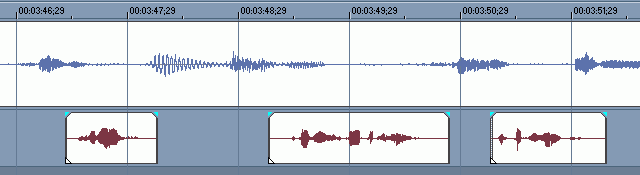
В этом случае перевод нужно класть так, чтобы следующая фраза актёра начиналась сразу за окончанием перевода предыдущей фразы. Этот же метод применим и к длинным монологам.
Случай бурного диалога.
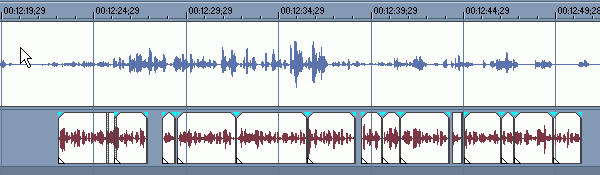
Здесь стОит просто выделить ключевые фразы актёров, которые будут выделяться паузами в переводе и подогнать дикторский текст, вырезая, где можно, лишние паузы и оговорки.
Несколько общих советов. Во время шумных сцен не стоит переводить крики, типа "Come on!", "Let's go!", "Wow!", "I'll Be Back.", а также имена собственные. Некоторые повторы тоже можно игнорировать. Пример: "I love you..." - "Я люблю тебя.", "I love you!" - "Она повторила эту фразу второй раз." Не нужно дважды переводить одно и то же. Однако, в комедийных сценах это может быть оправдано. Ещё по поводу шумных сцен. Старайтесь класть перевод между выстрелами и взрывами, если надо, то и в момент произнесения фразы актёром, полностью перекрывая его текст, мы же не хотим изуродовать динамику оригинала, понижая уровень громкости стрельбы?
Итак, режем и двигаем, режем и двигаем, пока не закончится саундтрек или терпение. Процесс занимает несколько дней в режиме хобби.
Ctrl+S!
Самое время разобраться с обработкой. При установке, Вегас инсталирует кучу плагинов, из которых нам понадобятся только Smooth/Enhance и Multi-Band Dynamics. Кроме того, придётся прикупить (прикупить - это такой эффемизм) пакет плагинов TC Works Native Bundle VST. Поскольку Вегас в чистом виде не понимает VST плагины, то мы их будем подгружать через Cakewalk VST Adapter. Эта связка работает не очень надёжно, по крайней мере у меня, так что приготовьтесь к некоторым обломам, типа "Вегас выполнил недопустимую операцию". Возможно, другие VST адаптеры работают лучше, но мне влом проверять. На самом деле, всё работает нормально, просто надо помнить, что сначала нужно вскипятить воду, а уже потом бросать макароны. Но об этом позже.
Итак, первым делом настроим Cakewalk VST Adapter.
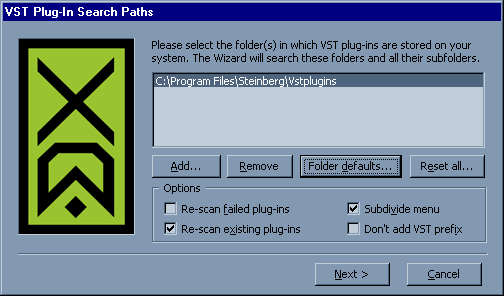
Здесь просто надо указать диру, в которую вы установили TC Works Native Bundle и установить галки, как показано на скриншоте, после чего несколько раз нажать кнопку Next и, наконец, Finish. Всё! Про настройку адаптера можно забыть до тех пор, пока мы не захотим приручить другие свежеустановленные плагины. Похоже, стандарт плагинов DirectX потихоньку загибается в среде профессиональных продуктов, а VST набирает силу день ото дня. Во всяком случае, последняя версия TC Works Native Bundle для DX так и осталась 2.02 бета, а для VST - 3.0, собственно, которую мы и будем использовать. Кроме того, так будет удобнее и для тех, кто захочет повторить мои упражнения в Nuendo. Для страстных поклонников плагинов от Waves могу добавить, что плагины от TC Works ничуть не хуже по качеству и являются, что называется, маст хэв.
Ладно, займёмся делом. Запускаем Вегас. Он автоматически загрузит наш сохранённый проект. Всё-таки приятно полюбоваться на столь кропотливую нарезку :) Бросим на таймлайн ещё два файла: левый и правый фронтальные каналы и уберём с образовавшихся треков всю обработку, как это описано в первой части.
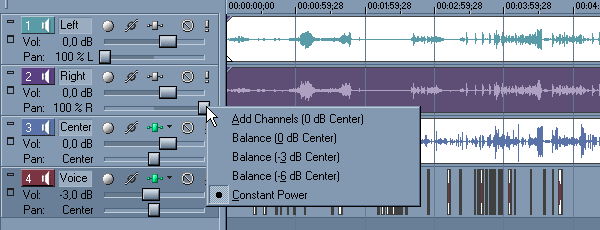
Перетащим эти треки наверх, чтобы они нам не мешались, следующим непростым способом: ЛК на пустой области слева от слова Pan: и, не отпуская кнопки, тащим трек наверх. Да! Забыл объяснить, нафига нам вообще эти дорожки нужны на данном этапе. Ну, теоретически, и без них можно обойтись, а практически весьма полезно будет слышать общую стереокартину фронта. Теперь сдвинем фейдеры баланса (Pan:) до упора влево и вправо соответственно для левого и правого каналов фронта. Теперь немножко занудства на тему, как в Вегасе работает панорамирование. Вегасу абсолютно наплевать, какие файлы мы ему подсовываем, моно или стэрео, он их все считает стереофоническими и панорамирует по умолчанию следующим образом: при перемещении фейдера влево происходит постепенное подмешивание сигнала из правого канала в левый с затуханием в правом, короче, если ползунок полностью увести влево или вправо, мы получим сумму левого и правого каналов в левом или в правом соответственно. Разумеется, такой канал будет звучать в два раза громче. Этот режим панорамирования и есть Add Channels. ПК на фейдере и из меню выбираем Constant Power. Это тот самый режим, что нам нужен, то есть при перемещении фейдера влево просто уменьшается громкость правого канала и наоборот. Объяснение звучит довольно бестолково, я и сам толком не понимаю, что я тут накалякал. Давайте сделаем так: нажмём на значок "Восклицательный Знак" в области регулировок трека, в котором будем упражняться. Этим мы включим режим Solo для данного трека и будем слышать только его. Включаем попеременно то Add Channels, то Constant Power и двигаем фейдер баланса влево-вправо, засекая по индикатору громкость. Ага! В режиме Add Channels индикатор шкалит, и уровень выпрыгивает за пределы нулевой отметки, а в Constant Power всё в порядке. Его-то и оставим :).
Ладно, с этой шнягой мы разобрались. Переходим к самому противному, к обработке. Тут нас ждёт масса подводных камней и течений, с которыми вам, как художнику, придётся бороться самостоятельно, я лишь обозначу азимут. Неизбежны находки и провалы, в какой-то момент вам захочется бросить всё, как это было в первой части, швыряние палитры и кистей на пол, слёзы и причитания с припаданием на тёплую грудь жены, крики о том, что вы бездарный мазила и не стОите высокого звания художника с большой буквы Х и тэдэ и тэпэ. Это пройдёт :).
Всё правильно, будем компрессировать трек перевода. Только не так, как вы подумали, а лишь выборочные сегменты частот. Если вы помните, в первой части я говорил, что работать мы будем с уже обработанным файлом. Я имел ввиду, что голос уже обработан компрессором и экспандером/гейтом. Как правило, такие записи делаются в щадящем для динамики режиме, и это представляется мне правильным. Я не люблю, когда динамический диапазон слишком заужен. Озвучивая фильм, диктор сам говорит то громче, то тише, в зависимости от зашумлённости саундтрека. Это чистая физиология. На этом-то мы и сыграем. Единственное, что мы попытаемся снивелировать, это задувания в микрофон и звонкое цыкание-сыкание. Задуваний, конечно, лучше всего избежать в момент записи, это ошибка звукорежиссёра, неправильно установившего микрофон, лечить это без потерь низких частот невозможно. Правда, в данном конкретном случае эти самые низкие частоты в голосе нам и не нужны. Чёрт его знает, что там за неравномерность частотной характеристики у центральной колонки? Как начнёт басо-бубнить в самое неподходящее время :). Да и разборчивость речи увеличивается. А вот насчёт цыкания-сыкания, это уже от дикции зависит. Я знавал дикторов, которые целыми днями ходили и на разные лады сыкали и шыкали: "Шла Саша по шоссе и сосала сушку! И ссоссала, и ссосссала, и соссссала сссушшшшку!". Избавлялись, понимаешь, от природного дефекта :) Слава Богу, современные диэссеры довольно чистенько справляются с этой проблемой, если случай не самый клинический.
Ладно, хватит болтовни. Жмём кнопку  TrackFX голосовой дорожки и в открывшемся окне двойным щелком (далее ДК - дабл клик) выбираем Multi-Band Dynamics. Нажимаем ОК в правом верхнем углу и видим следующую картинку:
TrackFX голосовой дорожки и в открывшемся окне двойным щелком (далее ДК - дабл клик) выбираем Multi-Band Dynamics. Нажимаем ОК в правом верхнем углу и видим следующую картинку:
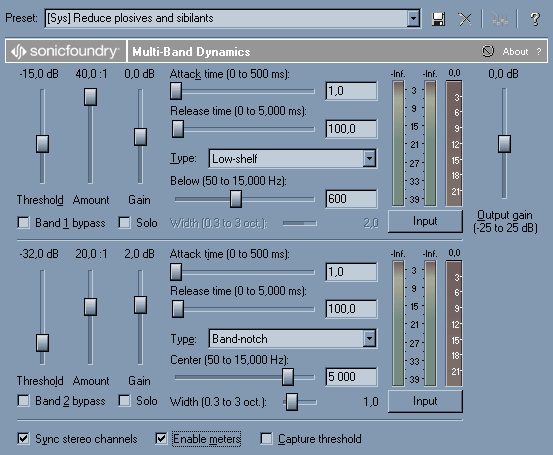
Пресет Reduce plosives and sibilants именно то, что нам надо. Чуть подробнее о том, как работает компрессор, я, может быть, расскажу позже, а пока нам важна только регулировка Threshold. Верхняя секция отвечает за задувания в микрофон, а нижняя за цыкание. По умолчанию этот пресет работает превосходно, однако в некоторых редких случаях регулировка Threshold всё же желательна. Чем меньше в математическом смысле число децибел этой регулировки, тем эффективнее подавляются недостатки. Это всё, что нужно запомнить на этом этапе. Не закрывая этого окна, переведите голосовую дорожку в режим Solo и начните воспроизведение трека. Двигая эти ручки вверх-вниз попробуйте добиться наиболее близкого к ожидаемому результата. Тут вам советчик только ваш слух. Подсказка: попробуйте регулировать с нажатой на клавиатуре кнопкой Ctrl. Кстати, сочетание Ctrl+Click работает на всех фейдерах в продуктах от Sonic Foundry/Sony. Итак, движки подёргали, звук устраивает... Всё, перекур! Уходим на десять-пятнадцать минут, курим, пьём кофе, целуем жену и детей. Возвращаемся. Хе-хе :) Надо крутить всё сначала :) Уже не устраивает :). Это нормально. Просто поднимите движки на пару децибел вверх, и всё устаканится. Закрываем это окно эффектов и выключаем режим Solo.
Пора сбалансировать громкость перевода с саундтреком вчерне. Найдём более менее спокойную беседу и послушаем, насколько громко звучит перевод. Ползунком Vol: настоим так, чтобы и диалог звучал отчётливо, и переводчика можно было улавливать не напрягаясь. Теперь найдем в саундтреке громкое место и убедимся, что переводчика, по крайней мере слышно. Поднимем громкость на пару децибел, чтобы голос обозначился более явственно. Я хочу сказать, что в громких местах нужно добиться, чтобы переводчика было хотя бы слышно, пусть и не разбирая некоторых слов. Конечно, в тихих местах он будет звучать несколько громче, но это и к лучшему, а то вы и так его слишком утопили :) Всё! Черновой баланс громкости отстроен. Курим, пьём кофе, закусываем бутербродами.
Немного о связи громкости и обработки. Любая обработка, которую мы накладываем на трек, работает pre-fader, то есть громкость регулируется уже после того, как трек обработался эффектом. Это я к тому, что повторно Threshold регулировать не надо :).
Пока я тянул резину с окончанием статьи, вышел новый Вегас 4.0е билд 239. Всё, теперь тоже под лейблом Сони :), правда всё равно устанавливается по дефолту в папку c:\program files\sonic foundry. Не советую менять путь. Объяснить, почему, не могу, чисто на уровне интуиции. У меня ещё установлен Саунд Фордж 7а, вот он встал в папку Сони, так что пользуется своими личными плагинами. Кстати, всем кто измучился с кнопкой Custom настройки плагинов, советую в реестре удалить параметр "key1" в [HKLM\SOFTWARE\Sonic Foundry\MC MPEG Plug-In\1.0\License], [HKLM\SOFTWARE\Sonic Foundry\AC-3 Encoder\1.0\License] для Вегаса, а для Саунд Форджа - в [HKLM\SOFTWARE\Sony Media Software\MC MPEG Plug-In\1.0\License]. Эта проблема известна давно, ещё со второй версии Вегаса, и подробно была описана на официальном форуме поддержки пользователей продуктов Sonic Foundry, просто проявляется не на каждом компьютере и зависит от серийного номера плагина. Этот рецепт взят именно оттуда :).
Теперь приступим к тонкой настройке баланса громкости перевода и оригинала. ПК на кнопке дорожки перевода и из меню выбираем Plug-In Chooser.
ДК на VST SideChainer и ОК в правом верхнем углу.
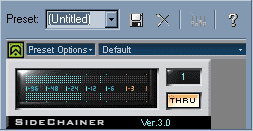
Здесь уже всё настроено правильно, нужно только убедиться, что кнопочка THRU активирована, то есть подсвечена жёлто-оранжевеньким.
Дальше. ЛК на кнопке дорожки центрального канала и выбираем VST Compressor DeEsser.
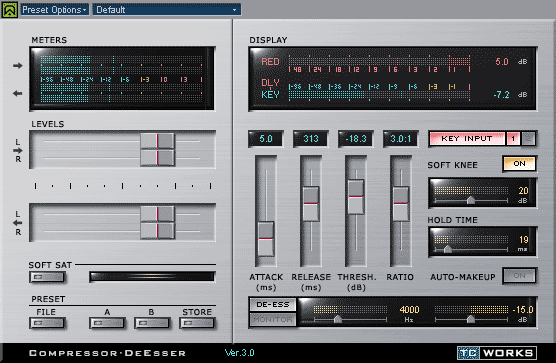
Очень важно: все VST плагины нужно добавлять при остановленном воспроизведении, иначе Вегас может стошнить. И уж совершенно точно его заколбасит, если, при включённом SideChainer, на VST Compressor DeEsser не нажать кнопку KEY INPUT и начать воспроизведение. Так что нажмите её сразу! Чтобы не тянуть, по-быстрому сделайте такие же настроечки, как на картинке, и послушайте громкое место саундтрека. Не правда ли, волшебно? :) Нет? Сейчас будем крутить ручки :).
Но прежде попробуем разобраться, как вся эта фигня летает. Итак, что мы сделали? Мы нарЕзали перевод и правильно его расставили вдоль саундтрека. Ну, ещё слегка обработали, чтобы избавиться от мелких недостатков, и выровняли баланс громкости. Для мелодрам и шведских фильмов домашнего производства на этом, в принципе, можно и остановиться. Осталось только бросить на таймлайн остальные треки и свести всё в AC3. Но! Мы озвучиваем боевик :) Последние два плагина мы добавили исключительно из-за сцен, насыщеных музыкой, звуковыми эффектами и насилием. Шум шкварчащей яичницы, атомные взрывы, водопад, рёв раненого бизона - вот с чем нам предстоит бороться. Самый простой способ - убрать уровень громкости оригинала под переводом. Но при этом приглушатся и тихие звуки. Этот способ нам не подходит. Мы будем сигнал компрессировать, то есть делать потише только громкие звуки. Причём только тогда, когда появляется диктор, не затрагивая остальной части саундтрека. Для этого-то нам и понадобился VST Compressor DeEsser в центральном канале. Однако, как его заставить обрабатывать не всю дорожку, а только часть её, ту, что под переводом? Хе-хе :) Вижу, все уже догадались,VST SideChainer именно под это и заточен: давать команду VST Compressorу на обработку центрального канала при появлении сигнала с дорожки перевода. Итак, сразу стало понятно, как работает эта связка VST SideChainer - VST Compressor DeEsser. Именно благодаря ей мы добьёмся того, что понижение уровня громкости центрального канала на слух будет практически незаметно. Этот способ обработки сигнала называется "autoduck", если я не ошибаюсь, и довольно широко применяется в радиовещании, а это программная его реализация. Самое время подёргать движки компрессора. Пройдёмся немного по интерфейсу. Секция Meters: верхний индикатор показывает уровень сигнала до обработки, а нижний - после. Секция Levels предназначена для подстройки громкости на входе и после обработки. Не надо здесь ничего регулировать! Эти движки полезны при полной обработке файла, но никак не в нашем случае. Секция Display: нижний индикатор (KEY) показывает уровень сигнала с дорожки перевода, а верхний (RED) степень компрессии обрабатываемого, то есть, центрального канала. Кнопка KEY INPUT включает режим срабатывания компрессора от команды VST SideChainer. Там ещё есть кнопочки 1 (уже активирована) и 2 на тот случай, если вам захочется на какой-то другой канал повесить ещё один VST SideChainer. Например, на дорожку с голосом переводчицы :), которую мы, естественно, предварительно обрабатываем несколько иначе, нежели мужской голос. Правда, в этом случае понадобится на центральный канал повесить ещё один VST Compressor DeEsser и заточить его на KEY INPUT 2. Помните шикарную дикторшу-переводчика из фильма "Бриллиантовая рука"? "Непереводимый итальянский фольклор" Хе-хе :)) Сейчас таких не делают. (Кстати, слово фольклор произносится как [фалькль`ор]. Извиняюсь за офтопик, но наболело: ну, нету в русском языке слов потрясно и волнительно! НЕТУ! Есть потрясающе и волнующе. Козлы. Задолбали рекламой товаров для устранения последствий метаболизма :)) Но мы отвлеклись. Нет, ***, пойду перекурю сначала...
Мы подобрались к самому главному процессу в наших настройках. Крутим ручки компрессора. Для начала я попробую объяснить, как работает связка VST SideChainer - VST Compressor DeEsser, не прибегая ко всяким графикам и чертежам и не запудривая мозг околозвукорежиссёрским пафосом. Отмазка: всё, что я опишу ниже, основано исключительно на интуиции и не подкреплено никакими теоретическими знаниями. Честно говоря, мне глубоко наплевать на любые цифры и синусоиды, я ориентируюсь только на свой вкус и слух. Я вообще могу и буду использовать компрессор как эквалайзер, и никто мне не запретит. Вам - тоже :) Нужно учесть, что всё, что я скажу, относится только к нашей ситуации. В чистом виде компрессор работает несколько иначе.
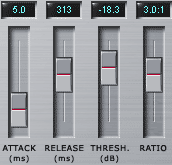
В нашем случае компрессор следит за уровнем громкости сигнала и начинает его (сигнал) обрабатывать только тогда, когда этот уровень достигает определённого значения и есть команда от SideChainerа. Это и есть Threshold, то есть, порог срабатывания. Какой именно порог выставить? Давайте найдём в нашем саундтреке тихое место, например, разговор на лоне природы. Прямо при воспроизведении начинаем аккуратно двигать ручку Threshold, пока не добьёмся синхронной работы индикаторов секции Meters. Ну, может быть, индикатор обработанного сигнала будет показывать чуть меньший входного уровень в момент перевода. Всё. Работу компрессора в тихих местах мы настроили. Идём дальше. Как только компрессор обнаруживает, что громкость сигнала выше порога, он начинает эту громкость понижать. Ну, конечно, он это делает не тупо, а в зависимости от положения ручки RATIO (отношение). В верхнем положении (1:1) никакой обработки не происходит вообще. Чем ниже ручка, тем сильнее подавляется сигнал. Тут важно не переборщить. Найдём громкое место и выставим такое RATIO, при котором переводчика разборчиво слышно. В принципе, вся настройка закончена. Остались сущие пустяки. Что происходит в моменты, когда компрессор начинает и заканчивает обработку? За скорость срабатывания отвечает ручка ATTACK. Чем ниже ручка, тем быстрее начинается понижение громкости. На мой вкус, не стОит устанавливать слишком маленькое значение, пусть голос диктора чуть "наедет" на основной фон, как бы сольётся с ним. Но это не принципиально и дело вкуса. Теперь о том, как быстро восстанавливать громкость после обработки. За это отвечает последняя ручка - RELEASE (отпустить). Чем меньше её значение, тем быстрее восстанавливается громкость. Тут возможны варианты. Например, если мы не очень сильно подбирали громкость, то и восстановить её можно достаточно быстро, в противном случае лучше это делать медленно. В общем, значение RELEASE сильно зависит от положения ручки RATIO. Всё здесь зависит от вкуса звукорежиссёра. Для фильма "Леон" меня устроили значения, указанные на скриншотах :). Мне кажется, я достаточно сказал для того, чтобы у вас не возникало дополнительных вопросов, но и осталось поле для экспериментов. И напоследок несколько советов. Вроде бы все делается правильно, а звучит не очень: съедаются концы фраз диктора, звук центра понижается сильно, но диктора всё равно неразборчиво слышно... Похоже, диктор совсем не скомпрессирован. Добавьте в цепочку плагинов Track Compressor и выберите из пресетов наиболее подходящий, а чтобы сделать диктора поразборчивее, приберите у него низкие частоты или добавьте верхних. Это делается плагином Graphic EQ. Учтите, что в цепочке плагинов последним должен быть SideChainer, а предпоследним - Multi-Band Dynamics, им же можно прибирать и низкие частоты, я уже рассказывал, как. Мучения с настройкой этого всего хозяйства, конечно, невообразимые :), однако, результат того стОит. После того, как мы всё настроили, лучше всего, прерваться минут на пятнадцать, перекусить, покурить, перекинуться парой анекдотов с коллегами, а потом послушать снова. На очень маленькой громкости и на большой. Наверняка придётся что-то подстроить :))) Теоретически, после всех наших настроек мастер-индикатор Вегаса шкалить не должно. Проверим это. Отключим дорожки левого и правого канала, щёлкнув мышкой на значках "Не курить" 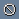 (Mute) соответствующих дорожек, и послушаем наиболее громкое место, глядя на индикатор. Повторяю ещё раз: шкалить не должно! В противном случае, что-то было не так сделано. Ещё раз проверьте все настройки плагинов.
(Mute) соответствующих дорожек, и послушаем наиболее громкое место, глядя на индикатор. Повторяю ещё раз: шкалить не должно! В противном случае, что-то было не так сделано. Ещё раз проверьте все настройки плагинов.
Ладно, всё, уже хочется готового АС3 файла! Переходим к сведЕнию. Бросаем на таймлайн оставшиеся файлы: сабвуферный и два задних. Убираем с них всю обработку. Жмём Alt+Enter и на закладке Audio изменяем Master Bus на 5.1 Surround. Пожалуй, надо ещё снять галочку с Enable low-pass filter on LFE. Нажимаем ОК, и вот что у нас получилось:
Итак, что мы видим? Вместо ползунка баланса у нас теперь полноценное пространственное панорамирование, появился Surround Panner. Красными ромбиками обозначено положение каждого трека в пространстве. Распихайте их по нужным местам. Я это уже сделал :). Да! ПК на Surround Panner дорожки баса и в меню выберите LFE only. Ну, ещё можно ЛК на всех лишних синих спикерах в каждом Surround Pannerе, чтобы быть уверенным, что туда ничего не просочится. Теперь давайте вспомним всё, что мы говорили о панорамировании раньше. Здесь работает тот же принцип, поэтому мы должны сделать так: ПК на Surround Panner, меню->Pan Type->Constant Power. Особое внимание нужно уделить центральному каналу. Он у нас состоит из двух дорожек: Center и Voice. ДК на Surround Panner каждой из этих дорожек, появится окно Very Big Surround Panner c ползуночком громкости в нижней части. ДК на этом ползуночке, и он встанет в нулевую позицию. Теперь у нас есть центральный канал :). Закрываем Very Big Surround Panner. Так, чего бы ещё полезного сделать? Вот! Повесим-ка мы ещё на каждую дорожку, кроме LFE и Voice, такой плагинчик, как Smooth/Enhance и в его пресетах выберем Boost high frequencies. Этот плагин что-то делает с высокими частотами, типа реставрации. Звучит, как очень лёгкий эксайтер. Необходимость его применения весьма сомнительна, но я утешаю себя мыслью, что он немного восстанавливает утерянные при оригинальном кодировании в АС3 частоты. Короче, можете не ставить :) Слушаем, что у нас получилось, и убеждаемся в собственной гениальности :). Всё, кайф словили, полюбовались, как дергаются индикаторы в Surround Mastere, пора делать АС3 файл.
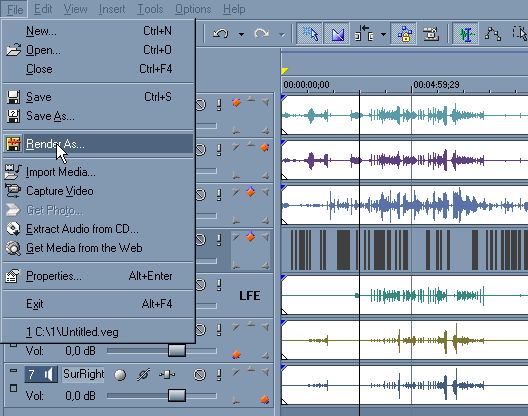
Вот как выглядит окно проекта перед кодированием. (Скажу по-секрету: после кодирования оно будет выглядеть точно так же :) Из меню Вегаса выбираем Render As. В окне сохранения Save As Type: Dolby Digital AC-3, конечно же. Template: 5.1 Surround DVD, в принципе, то что надо, однако битрейт этой заготовки 448 Kbps, что может быть не всегда удобно и правильно. Тема битрейта достаточно хорошо освещена у нас на форуме, поэтому я не буду размазывать манную кашу по скатерти, а сразу перейду к настройкам. Жмём кнопку Custom.
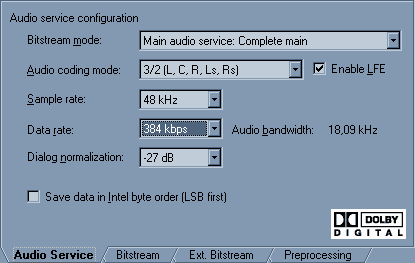
На первой закладке (Audio Service) изменяем Data Rate на 384 kbps, это вполне достаточный битрейт. Вегас будет ругаться, что это не вписывается в DVD стандарты, но мы-то с вами знаем :))) Кстати, вы не помните, с какими именно параметрами был закодирован оригинальный АС3, который мы распаковали? На самом деле, это и не важно. Вы знаете, в какой комнате и на каких колонках это всё оригинально делалось? Вот и я не знаю. Зато мне точно известно, что не на таких, как у меня :) Всё равно придётся звук затачивать под мои условия. Поэтому, все установки делаем стандартными. На закладке Bitstream они уже установлены. Эти установки важны только в случае стереофонического прослушивания всех каналов и указывают DVD плееру, каким образом подмешивать центральный и задние каналы к фронтальным. Переходим к закладке Preprocessing.
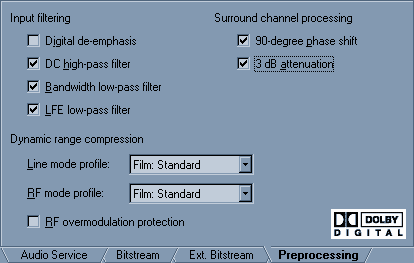
Всё, что здесь надо сделать, это поставить галку на 3 dB attenuation. Это заставит ресивер воспроизводить задние каналы на три децибела тише. Можете не ставить :) Честно говоря, мне влом рассказывать об этих настройках, тем более, что ничего, кроме битрейта менять не надо. Да это и неинтересно. Особо продвинутые и сами с этим разберутся, кнопку F1 пока никто не отменял :) Нажмите кнопочку ОК, а потом Save, подождите, пока закодируется, и можно делать с готовым АС3 файлом что угодно. Лично я его скармливаю Сценаристу, он его проглатывает, не жуя.
Всё :)
И напоследок. Что делать, если фильм в NTSC, а перевод от PAL? Или наоборот. Хе-хе :) Помните, как мы подрезали тишину между словами? Попробуйте сделать то же самое, но при нажатой клавише CTRL. Нравится? Точно так же можно и растягивать трек.
Если эта статья показалась вам полезной, пойдите в магазин, купите букет цветов и мороженное. Жене - цветы, детям - мороженное.
Успехов!
© 2003 crio


